
Machines with Imagination:
Learning from Description through Synthesis and Analysis
Overview
Abstract
In the Deep Intermodal Video Analytics (DIVA) project, we will develop an Analysis-by-Synthesis framework which takes advantage of state-of-the-art advancements both in graphical rendering engines (e.g., Unreal Engine) as well as machine learning to create an intelligent system that can learn to recognize activities from descriptions. Our system will break down a description of an activity into components and then synthetically realize different instances of the description visually to then teach a discriminative machine learning model to recognize this scenario in real data. The discriminative model will be compositional and take advantage of our prior work in human parsing from static photos, object recognition, and activity recognition.
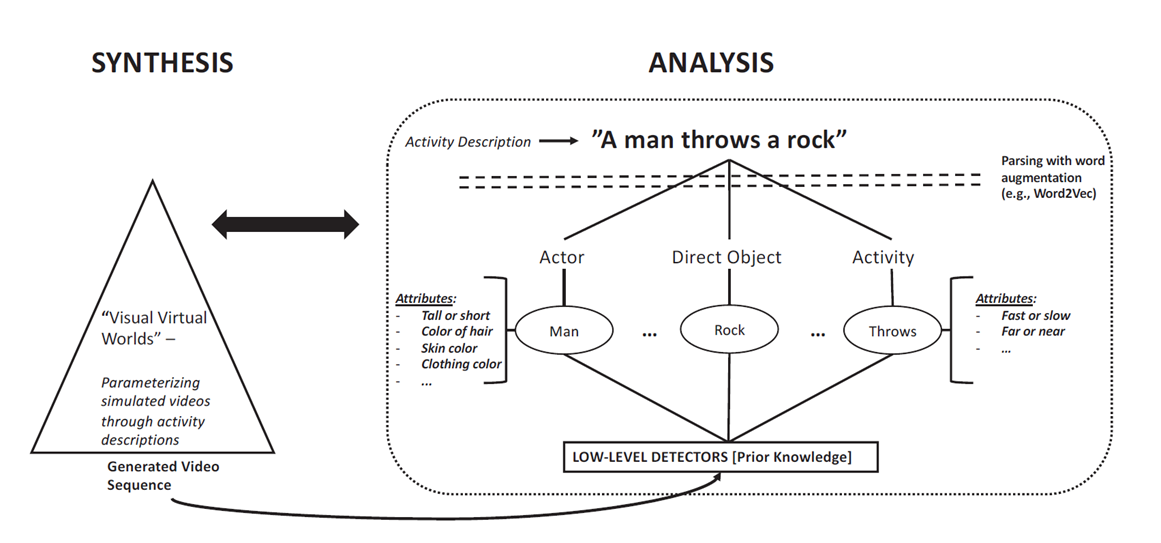
Figure 1: The proposed Analysis-by-Synthesis pipeline. Synthetic virtual world generates or “imagines” instances of activities given a semantic description. This is used to train discriminative models.
Data Synthesis
Graphical renderers like Unreal Engine 4 have become very photo-realistic. Such virtual environments allow computer vision models to obtain “free” depth, surface normal, and semantic maps. UnrealCV is an open source project mainly developed by Weichao Qiu that drives the data synthesis pipeline.

Figure 2: A generated photo-realistic scene with accurate segmentation masks, depth maps and surface normals.
The parameterized data synthesis pipeline through UnrealCV enables us to generate virtual training data that closely mimics real scenes of interest. Such data can be generated at scale and contains rich supervisory signal that computer vision models can benefit from.

Figure 3: The left image is a sample scene from DIVA training data set. The right image is an example scene from the synthesis pipeline.
Analysis by Synthesis
Figure 4 shows a high-level overview of the synthesis procedure. In essence, we create a function that is parameterized by: an activity class A, one or more objects O that support the activity, and a pre-learned distribution of sequential human joint configurations that describe the motion of a person performing the activity. As there are often variants on how an activity may be realized, with respect to
the motion of the actor(s), this procedure allows the synthesizer to visually generate different depictions of how the activity may come to form. The goal of Synthesis is then to map an activity description to a video sequence, and this may then be used to teach the Analysis to discriminatively recognize new activities.
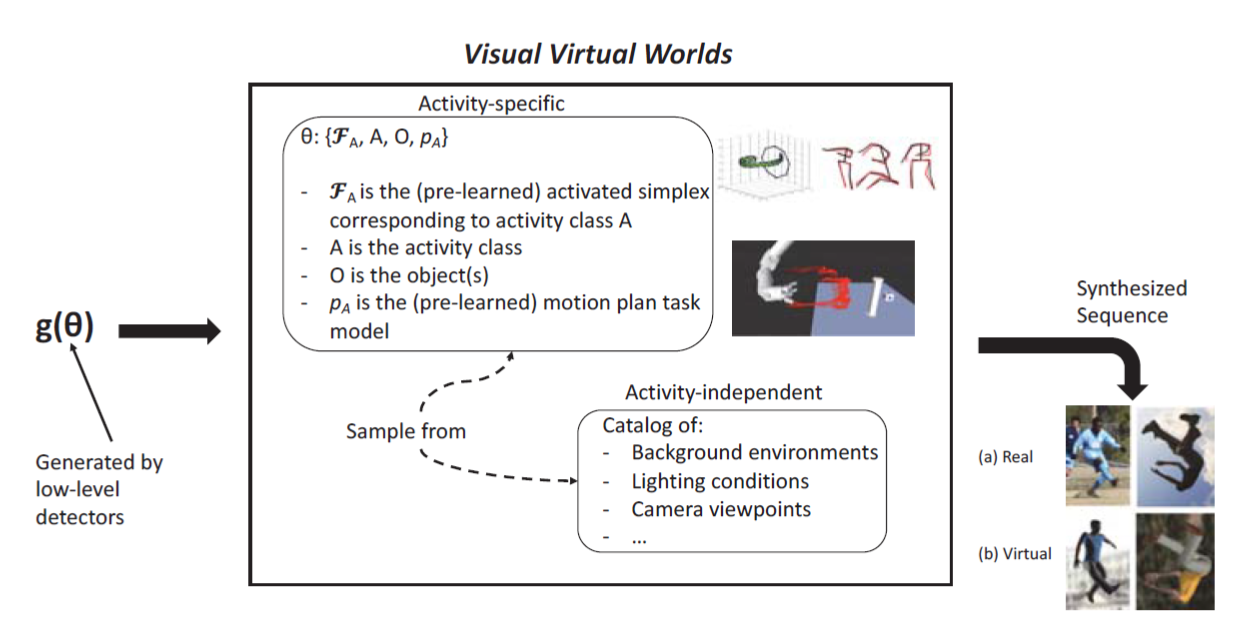
Figure 3: The left image is a sample scene from DIVA training data set. The right image is an example scene from the synthesis pipeline.
The fundamental premise of this approach is that both generation and detection/discrimination of activities can be attacked in a modular fashion that leverages data-driven “narrow AI” approaches. We do so in a framework that leverages growing evidence that simulation can be used as a valuable “prior” to train algorithms to interpret image-level information. The key elements of this approach are thus:
- From description to simulation: Descriptions are decomposed in consitutent elements that are either “things” (people, objects, activities), or attributes of “things” (tall man, white hair, brown suitcase, fast walking, etc). From these descriptions, we then synthesize data representing these things. This data will be both real data (e.g. from curated collections), simulated data sampled from realistic models and textures, and combinations thereof.
- From video to content: These image sequences are then processed using pre-trained semantic units tuned to the objects of interest. Our detectors will parse individual photos of scenes to identify 2D locations of body joints of humans (using 3D priors), 2D locations of objects, and object attributes using semantic segmentations of the scene. If objects or attributes appear that are not pre-trained but which are recognized within the semantic structure, units will be trained “on-the-fly” (using widely available 3D models and 2D textures in graphics marketplaces as well as image queries) to account for them. The result is a (relatively) low-dimensional time-series of part identities and locations
- From simulation to fine-grained activity units: Following on our prior work on activity analysis, we use the extracted frame-level content to extract (learn) local spatio-temporal patterns, which we refer to as spatio-temporal tokens (STTs). Through discriminative training using our recently developed Temporal Convolutional Network (TCN) approach, these tokens capture the common local properties of an activity, while suppressing content that is irrelevant to it. An activity thus becomes a distribution
over sequences of STTs, thus allowing powerful statistical representations to be applied. - From statistical model from symbolic representation: We hypothesis that there is a “language of spatio-temporal behavior” that mimics language itself. We will impose a high-level grammar on STTs, but use the generated training data to learn the relationship between the semantic tokens (e.g. walking into a bathroom) and the extracted low-level tokens. This training will also be performed
discriminatively, thus allowing the system to be “tuned” to be sensitive to any specific range of queries. In particular, this approach can be fine-tuned for a specific description if one is available.
Acknowledgement
Supported by the Intelligence Advanced Research Projects Activity (IARPA) via Department of Interior/ Interior Business Center (DOI/IBC) contract number D17PC00345. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright annotation thereon. Disclaimer: The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of IARPA, DOI/IBC, or the U.S. Government.”
References
- W. Qiu, A. Yuille. UnrealCV: Connecting Computer Vision to Unreal Engine. ECCVW, 2016
- Lea, M. D. Flynn, R. Vidal, A. Reiter, and G. D. Hager. Temporal convolutional networks for action segmentation and detection. CVPR, 2017.
- C. Li, M. Z. Zia, Q. Huy, X. Yu, G. D. Hager, M. Chandraker. Deep supervision with shape concepts for occlusion-aware 3d object parsing. CVPR, 2017.
- Kim and A. Reiter. Interpretable 3D human action analysis with Temporal Convolutional Networks. CVPRW, 2017.