
We seek to address three major challenges facing robots in the real world:
- Robots should be able to learn, both from their own experience and from that of experts.
- Robots need to be able to combine knowledge they have acquired in order to solve abstract, high-level goals.
- Robots need to act in ways that are intuitive to humans.
In short, our robots need to come up with common-sense plans that both accomplish their goals. We address this problem with a framework for learning actions from expert demonstrations, and with algorithms for reproducing these actions in complex environments.
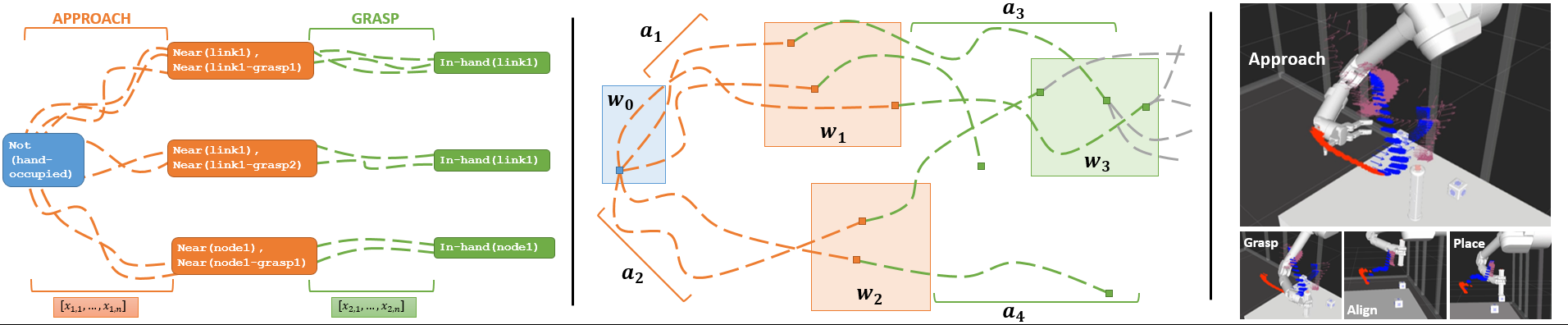
We propose a sampling based motion planning algorithm based on the Cross-Entropy Method for Motion Planning. Tasks are described through a high-level symbolic language such as PDDL or LTL, which determines a tree of possible actions that may lead to a successful goal. Each action takes us to a different symbolic state.
We then learn a stochastic policy over these discrete actions by sampling both discrete action choices and continuous policy parameterizations. In the graphic above, boxes represent symbolic world state and dashed lines represent trajectories. Different trajectories are sampled and weighted based on a model of expert behavior learned from demonstrations.
People Involved:
- Faculty: Greg Hager, Marin Kobilarov
- Students: Chris Paxton, Felix Jonathan