
Beyond Spatial Pooling, Fine-Grained Representation Learning in Multiple Domains
Abstract
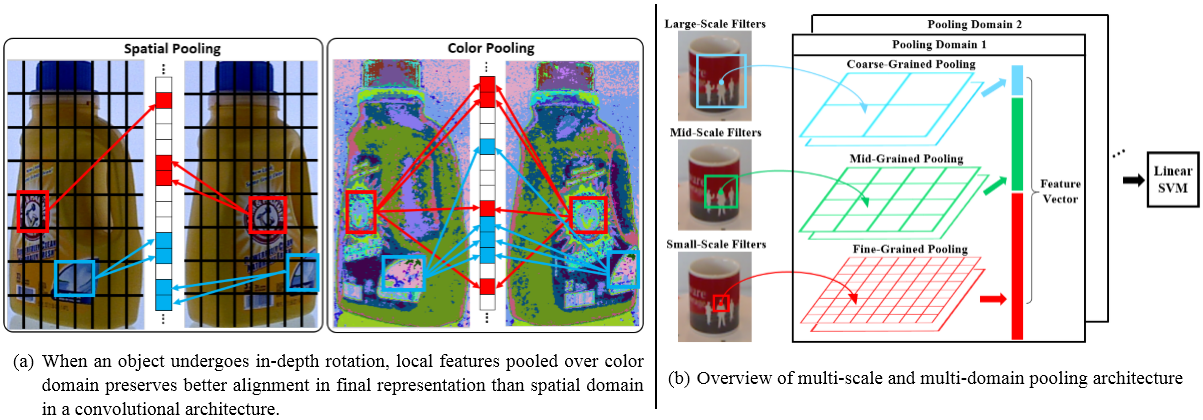
Object recognition systems have shown great progress over recent years. However, creating object representations that both capture local visual details and are robust to change in viewpoint continues to be a challenge. In particular, recent convolutional architectures now make use of spatial pooling to achieve scale and shift invariance, but are still sensitive to out-of-plane rotations due to the spatial image deformations they induce. In this paper, we formulate a probabilistic framework for analyzing the performance of pooling. This framework suggests two directions for improvement. First, we apply multiple scales of filters coupled with different pooling granularities, and second we make use of color as an additional pooling domain, thereby reducing sensitivity to spatial deformation. We evaluate our algorithm on an object identification task using two independent publicly available RGB-D datasets, and demonstrate significant improvement over the current state-of-the-art. In addition, we present a new dataset for industrial objects to further validate the effectiveness of our approach versus other state of the art approaches for object recognition using RGB-D data.
Paper
- Chi Li, Austin Reiter, Gregory D. Hager. Beyond Spatial Pooling, Fine-Grained Representation Learning in Multiple Domains. Proceedings of 28th IEEE Conference on Computer Vision and Pattern Recognition (CVPR2015).
Data
- The JHU-IT-50 dataset presented in the paper contains 50 industrial objects and hand tools frequently used in mechanical operations. Each object has 150 training examples captured at fixed viewing angles of 30, 45 and 60 degrees and 150 testing examples with completely random view points. All 50 objects are shown below:

- Download from here.
Other Materials
- Supplementary Material:
Due to the page limit, we moved a lot of technical details and numerical results into this file. This file also contains complete proofs for some conclusions in the original paper. - Extended Summary and Poster for CVPR 2015.