
Hierarchical Semantic Parsing for Object Pose Estimation
in Densely Cluttered Scenes
Abstract
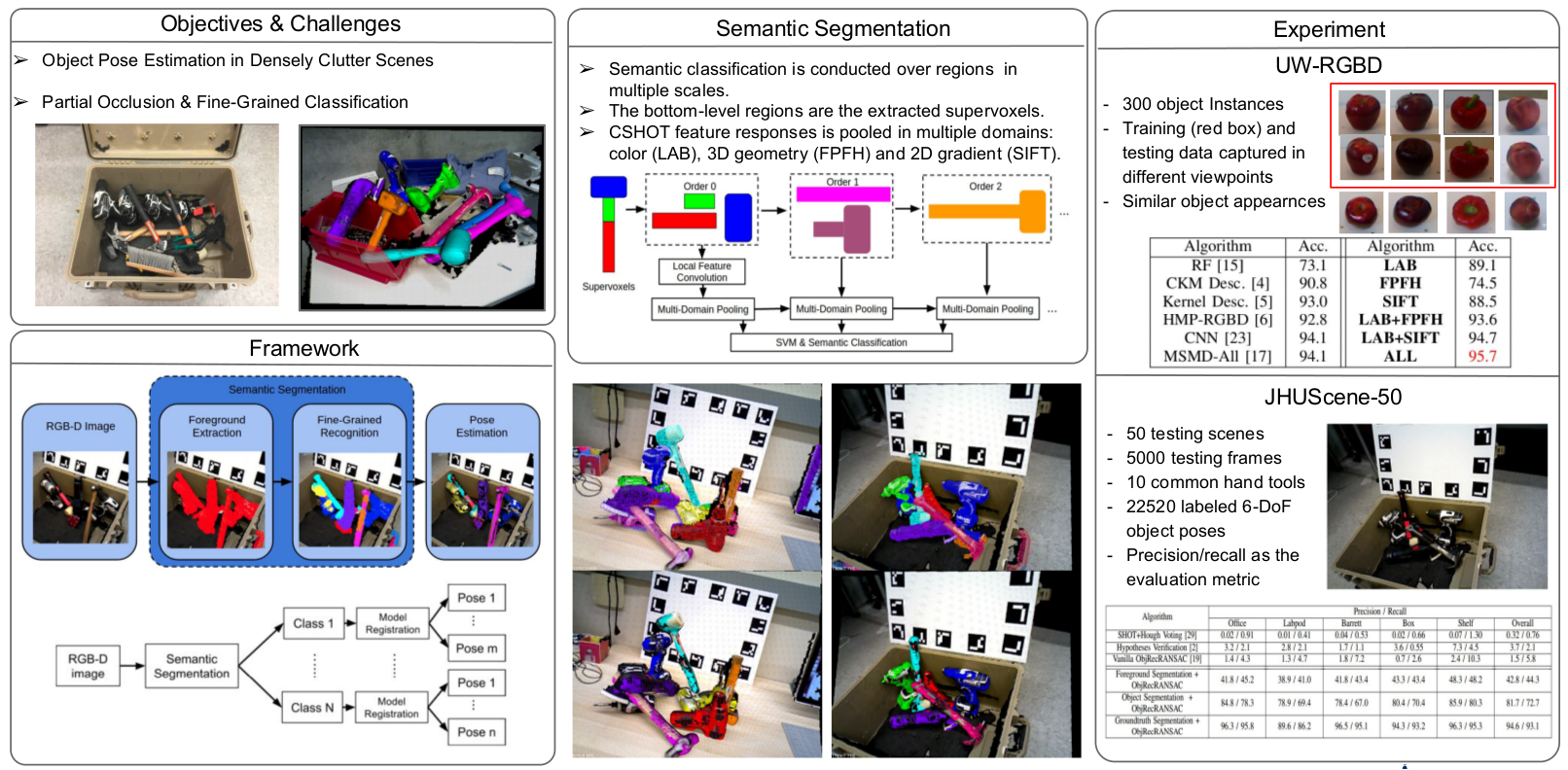
Object recognition systems have shown great progress over recent years. However, creating object representations that both capture local visual details and are robust to change in viewpoint continues to be a challenge. In particular, recent convolutional architectures now make use of spatial pooling to achieve scale and shift invariance, but are still sensitive to out-of-plane rotations due to the spatial image deformations they induce. In this paper, we formulate a probabilistic framework for analyzing the performance of pooling. This framework suggests two directions for improvement. First, we apply multiple scales of filters coupled with different pooling granularities, and second we make use of color as an additional pooling domain, thereby reducing sensitivity to spatial deformation. We evaluate our algorithm on an object identification task using two independent publicly available RGB-D datasets, and demonstrate significant improvement over the current state-of-the-art. In addition, we present a new dataset for industrial objects to further validate the effectiveness of our approach versus other state of the art approaches for object recognition using RGB-D data.
At a Glance
Video
Data
- The JHUScene-50 dataset contains 50 testing indoor scenes, 5000 testing frames, 10 common hand tools and 22520 labeled 6-DoF object poses. Precision/Recall is the evaluation metric. Each scene has at least 3 objects that are in close contact and reside in densely cluttered scenes.
- Download from here.

References
- Chi Li, Jonathan Bohren, Eric Carlson, Gregory D. Hager. Hierarchical Semantic Parsing for Object Pose Estimation in Densely Cluttered Scenes. Proceedings of IEEE International Conference on Robotics and Automation (ICRA), 2016.
- Chi Li, Austin Reiter, Gregory D. Hager. Beyond Spatial Pooling, Fine-Grained Representation Learning in Multiple Domains. Proceedings of 28th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
- Chi Li, Jonathan Boheren and Gregory D. Hager. Bridging the Robot Perception Gap With Mid-Level Vision. In International Symposium on Robotics Research (ISRR), 2015.