
Learning Convolutional Action Primitives
for Fine-grained Action Recognition
Abstract
Fine-grained action recognition is important for many applications of human-robot interaction, automated skill assessment, and surveillance. The goal is to segment and classify all actions occurring in a time series sequence. While recent recognition methods have shown strong performance in robotics applications, they often require hand-crafted features, use large amounts of domain knowledge, or employ overly simplistic representations of how objects change throughout an action. In this paper we present the Latent Convolutional Skip Chain Conditional Random Field (LC-SC-CRF). This time series model learns a set of interpretable and composable action primitives from sensor data. We apply our model to cooking tasks using accelerometer data from the University of Dundee 50 Salads dataset and to robotic surgery training tasks using robot kinematic data from the JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS). Our performance on 50 Salads and JIGSAWS are 18.0% and 5.3% higher than the state of the art, respectively. This model performs well without requiring hand-crafted features or intricate domain knowledge.
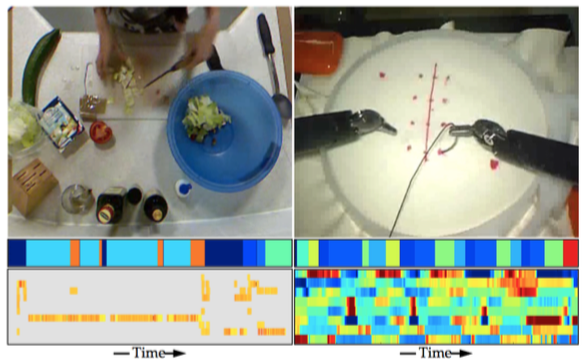
Example images from the 50 Salads and JIGSAWS datasets. Below each image is the sequence of actions over time and a visualization of the corresponding sensor signals. We see that each filter tends to model the transition between actions or different styles for performing an action.
At a Glance
Our Conditional Random Field model learns convolutional action primitives, action co-occurances, and temporal priors. For details see our ICRA paper below.
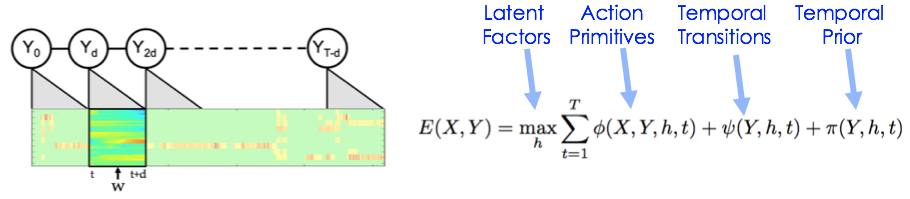
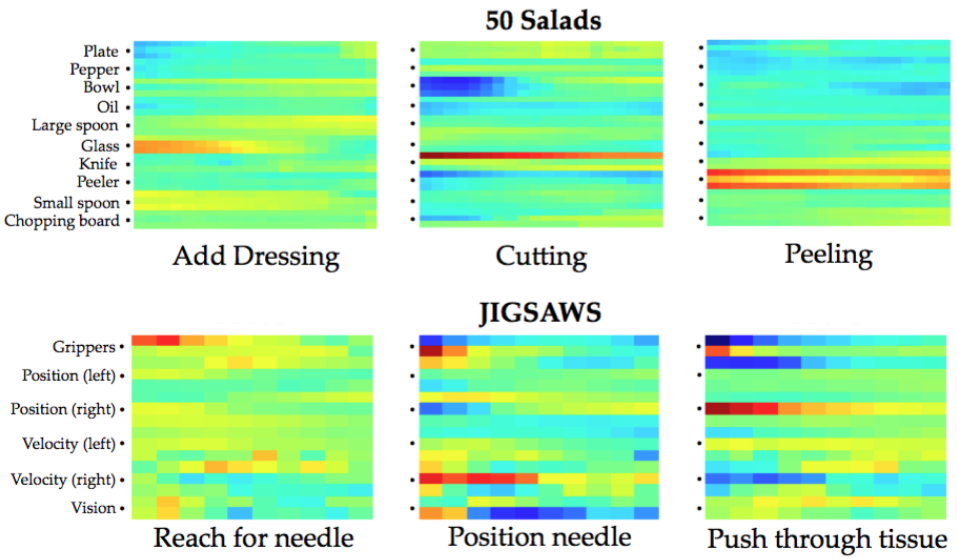
There are a set of action primitives for every action class which are learned discriminatively. Due to the model formulation, the learned primitives are relatively interpretable. Each filter below corresponds to one primitive. The X axis is time (e.g. over 5 seconds) and the Y axis represents sensor values. For 50 Salads we use accelerometers attached to 10 objects and for JIGSAWS we use the position, velocity, and gripper state for each arm of a DaVinci robot.
Code: https://github.com/colincsl/LCTM
References
- Learning Convolutional Action Primitives for Fine-grained Action Recognition. Colin Lea, Rene Vidal, Gregory D. Hager. ICRA 2016.
- An Improved Model for Segmentation and Recognition of Fine Grained Activities with Application to Surgical Training Tasks. Colin Lea, Gregory D. Hager, Rene Vidal. WACV 2015.
- Using Vision to Improve Activity Recognition for Surgical Training Tasks. Colin Lea, Gregory D. Hager, Rene Vidal. IROS Workshop on The Role of Human Sensorimotor Control in Surgical Robotics 2014.
<\ul>