
Segmental Spatio-Temporal CNNs for Fine-grained Action Segmentation
Abstract
Joint segmentation and classification of fine-grained actions is important for applications in human-robot interaction, video surveil- lance, and human skill evaluation. However, despite substantial recent progress in large scale action classification, the performance of state-of- the-art fine-grained action recognition approaches remains low. In this paper, we propose a new spatio-temporal CNN model for fine-grained ac- tion classification and segmentation, which combines (1) a spatial CNN to represent objects in the scene and their spatial relationships; (2) a temporal CNN that captures how object relationships within an action change over time; and (3) a semi-Markov model that captures transitions from one action to another. In addition, we introduce an efficient segmen- tal inference algorithm for joint segmentation and classification of actions that is orders of magnitude faster than state-of-the-art approaches. We highlight the effectiveness of our approach on cooking and surgical ac- tion datasets for which we observe substantially improved performance relative to recent baseline methods.
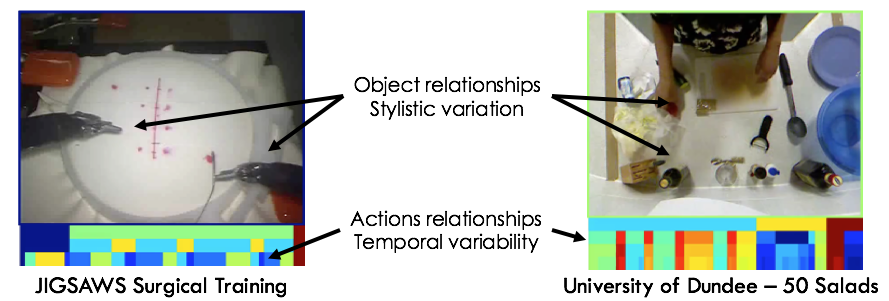
Figure: Example images from the 50 Salads and JIGSAWS datasets. Below each image is the sequence of actions over time at several different granularities (from course on top to fine on bottom).
At a Glance
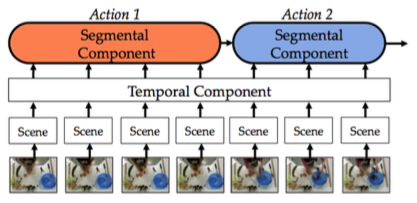
There are three components to our Segmental Spatial-temporal CNN. The spatial component models latent object representations in each region of the image. The temporal component captures action primitives (similar to what is seen here) and the segmental component ensures that we only predict a small set of actions. Details can be found in the paper below.
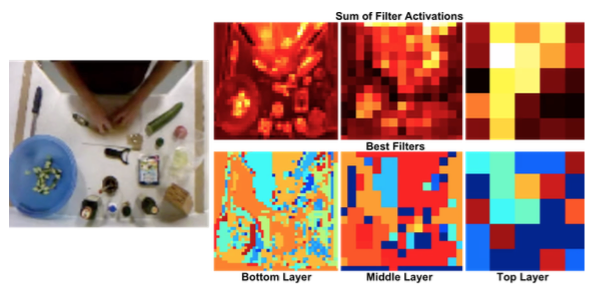
By visualizing the spatial CNN we see that the network tends successfully capture object-level information. The top row in the following 50 Salads image corresponds to which parts of the image receive the highest activations. The bottom rows show which CNN filters give the best scores for each location.
References
- Segmental Spatio-Temporal CNNs for Fine-grained Action Segmentation. Colin Lea, Austin Reiter, Rene Vidal, Gregory D. Hager. arXiv. 2016.